Bookmarks: Clear all bookmarks.
|
CTRL-SHIFT-F2
|
Bookmarks: Insert or remove a bookmark (toggle).
|
CTRL+F2
|
Bookmarks: Move to next bookmark.
|
F2
|
Bookmarks: Move to previous bookmark.
|
SHIFT+F2
|
Cancel a query.
|
ALT+BREAK
|
Connections: Connect.
|
CTRL+O
|
Connections: Disconnect.
|
CTRL+F4
|
Connections: Disconnect and close child window.
|
CTRL+F4
|
Database object information.
|
ALT+F1
|
Editing: Clear the active Editor pane.
|
CTRL+SHIFT+
|
Editing: Comment out code.
|
CTRL+SHIFT+C
|
Editing: Copy. You can also use CTRL+INSERT.
|
CTRL+C
|
Editing: Cut. You can also use SHIFT+DEL.
|
CTRL+X
|
Editing: Decrease indent.
|
SHIFT+TAB
|
Editing: Delete through the end of a line in the Editor pane.
|
CTRL+DEL
|
Editing: Find.
|
CTRL+F
|
Editing: Go to a line number.
|
CTRL+G
|
Editing: Increase indent.
|
TAB
|
Editing: Make selection lowercase.
|
CTRL+SHIFT+L
|
Editing: Make selection uppercase.
|
CTRL+SHIFT+U
|
Editing: Paste. You can also use SHIFT+INSERT.
|
CTRL+V
|
Editing: Remove comments.
|
CTRL+SHIFT+R
|
Editing: Repeat last search or find next.
|
F3
|
Editing: Replace.
|
CTRL+H
|
Editing: Select all.
|
CTRL+A
|
Editing: Undo.
|
CTRL+Z
|
Execute a query. You can also use CTRL+E (for backward compatibility).
|
F5
|
Help for SQL Query Analyzer.
|
F1
|
Help for the selected Transact-SQL statement.
|
SHIFT+F1
|
Navigation: Switch between query and result panes.
|
F6
|
Navigation: Switch panes.
|
Shift+F6
|
Navigation: Window Selector.
|
CTRL+W
|
New Query window.
|
CTRL+N
|
Object Browser (show/hide).
|
F8
|
Object Search.
|
F4
|
Parse the query and check syntax.
|
CTRL+F5
|
Print.
|
CTRL+P
|
Results: Display results in grid format.
|
CTRL+D
|
Results: Display results in text format.
|
CTRL+T
|
Results: Move the splitter.
|
CTRL+B
|
Results: Save results to file.
|
CTRL+SHIFT+F
|
Results: Show Results pane (toggle).
|
CTRL+R
|
Save.
|
CTRL+S
|
Templates: Insert a template.
|
CTRL+SHIFT+INSERT
|
Templates: Replace template parameters.
|
CTRL+SHIFT+M
|
Tuning: Display estimated execution plan.
|
CTRL+L
|
Tuning: Display execution plan (toggle ON/OFF).
|
CTRL+K
|
Tuning: Index Tuning Wizard.
|
CTRL+I
|
Tuning: Show client statistics
|
CTRL+SHIFT+S
|
Tuning: Show server trace.
|
CTRL+SHIFT+T
|
Use database.
|
CTRL+U
|

4 May 2015
SQL Server Shortcut Keys Enlisted
2 April 2015
SQL Server:: Log Shipping and Replication
Log shipping involves two copies of a single database that typically reside on different computers. At any given time, only one copy of the database is currently available to clients. This copy is known as the primary database. Updates made by clients to the primary database are propagated by means of log shipping to the other copy of the database, known as the secondary database. Log shipping involves applying the transaction log from every insertion, update, or deletion made on the primary database onto the secondary database.
Log shipping can be used in conjunction with replication, with the following behavior:
- Replication does not continue after a log shipping failover. If a failover occurs, replication agents do not connect to the secondary, so transactions are not replicated to Subscribers. If a failback to the primary occurs, replication resumes. All transactions that log shipping copies from the secondary back to the primary are replicated to Subscribers.
- If the primary is permanently lost, the secondary can be renamed so that replication can continue. The remainder of this topic describes the requirements and procedures for handling this case. The example given is the publication database, which is the most common database to log ship, but a similar process can also be applied to subscription and distribution databases.
Note:- We recommend using database mirroring, rather than log shipping, to provide availability for the publication database.
Requirements and Procedures for Replicating from the Secondary If the Primary Is Lost
Be aware of the following requirements and considerations:
- If a primary contains more than one publication database, log ship all of the publication databases to the same secondary.
- The installation path for the secondary server instance must be the same as the primary. User database locations on the secondary server must be the same as on the primary.
- Back up the service master key at the primary. This key will be restored at the secondary. For more information.
- Log shipping does not guarantee against data loss. A failure on the primary database can result in the loss of data that has not yet been backed up or for backups that are lost during the failure.
Log Shipping with Transactional Replication
For transactional replication, the behavior of log shipping depends on the sync with backup option. This option can be set on the publication database and distribution database; in log shipping for the Publisher, only the setting on the publication database is relevant.
Setting this option on the publication database ensures that transactions are not delivered to the distribution database until they are backed up at the publication database. The last publication database backup can then be restored at the secondary server without any possibility of the distribution database having transactions that the restored publication database does not have. This option guarantees that if the Publisher fails over to a secondary server, consistency is maintained between the Publisher, Distributor, and Subscribers. Latency and throughput are affected because transactions cannot be delivered to the distribution database until they have been backed up at the Publisher; if your application can tolerate this latency, we recommend that you set this option on the publication database. If the sync with backup option is not set, Subscribers might receive changes that are no longer included in the recovered database at the secondary server.
To configure transactional replication and log shipping with the sync with backup option
- If the sync with backup option is not set on the publication database, execute sp_replicationdboption '<publicationdatabasename>', 'sync with backup', 'true'. For more information.
- Configure log shipping for the publication database.
- If the Publisher fails, restore the last log of the database to the secondary server, using the KEEP_REPLICATION option of RESTORE LOG. This retains all replication settings for the database. For more information.
- Restore the msdb database and master databases from the primary to the secondary. For more information, If the primary was also a Distributor, restore the distribution database from the primary to the secondary.These databases must be consistent with the publication database at the primary in terms of replication configuration and settings.
- At the secondary server, rename the computer and then rename the SQL Server instance to match the primary server name. For information about renaming the computer, see the Windows documentation. For information about renaming the server.
- At the secondary server, restore the service master key that was backed up from the primary.
To configure transactional replication and log shipping without the sync with backup option
- Configure log shipping for the publication database. For more information.
- If the Publisher fails, restore the last log of the database to the secondary server, using the KEEP_REPLICATION option of RESTORE LOG. This retains all replication settings for the database.
- Restore the msdb database and master databases from the primary to the secondary. If the primary was also a Distributor, restore the distribution database from the primary to the secondary.These databases must be consistent with the publication database at the primary in terms of replication configuration and settings.
- At the secondary server, rename the computer and then rename the SQL Server instance to match the primary server name. For information about renaming the computer, see the Windows documentation. For information about renaming the server.You might receive an error message from the Log Reader Agent that the publication database and the distribution database are not synchronized.
- At the secondary server, restore the service master key that was backed up from the primary.
- Execute sp_replrestart. This stored procedure can be used to force the Log Reader Agent to ignore all the previous replicated transactions in the publication database log. Transactions applied after the completion of the stored procedure are processed by the Log Reader Agent.
- Restart the Log Reader Agent after the stored procedure executes successfully.
- Transactions that have already been distributed to Subscriber might be applied at the Publisher. To ensure that the Distribution Agent does not fail with an error when attempting to reapply these transactions at a Subscriber, specify the agent profile titled Continue On Data Consistency Errors.
Log Shipping with Merge Replication
Follow the steps in the procedure below to configure merge replication and log shipping.
To configure merge replication and log shipping
- Configure log shipping for the publication database. For more information.
- If the Publisher fails, at the secondary server, rename the computer and then rename the SQL Server instance to match the primary server name. For information about renaming the computer, see the Windows documentation. For information about renaming the server.
- Restore the last log of the database to the secondary server, using the KEEP_REPLICATION option of RESTORE LOG. This retains all replication settings for the database.
- Restore the msdb database and master databases from the primary to the secondary. If the primary was also a Distributor, restore the distribution database from the primary to the secondary.These databases must be consistent with the publication database at the primary in terms of replication configuration and settings.
- At the secondary server, restore the service master key that was backed up from the primary. For more information.
- Synchronize the publication database with one or more subscription databases. This allows you to upload those changes made previously in the publication database, but not represented in the restored backup. The data that can be uploaded depends on the way in which a publication is filtered:
- If the publication is not filtered, you should be able to bring the publication database up-to-date by synchronizing with the most up-to-date Subscriber.
- If the publication is filtered, you might not be able to bring the publication database up-to-date. Consider a table that is partitioned such that each subscription receives customer data only for a single region: North, East, South, and West. If there is at least one Subscriber for each partition of data, synchronizing with a Subscriber for each partition should bring the publication database up-to-date. However, if data in the West partition, for example, was not replicated to any Subscribers, this data at the Publisher cannot be brought up-to-date. In this case, we recommend reinitializing all subscriptions so that the data at the Publisher and Subscribers converges. For more information.
If you synchronize with a Subscriber that is running a version of SQL Server prior to SQL Server 2005, the subscription cannot be anonymous; it must be a client subscription or server subscription (referred to as local subscriptions and global subscriptions in previous releases). For more information.
30 March 2015
SQL Server :: How Transactional Replication Works
Transactional replication is implemented by the SQL Server Snapshot Agent, Log Reader Agent, and Distribution Agent. The Snapshot Agent prepares snapshot files containing schema and data of published tables and database objects, stores the files in the snapshot folder, and records synchronization jobs in the distribution database on the Distributor.
The Log Reader Agent monitors the transaction log of each database configured for transactional replication and copies the transactions marked for replication from the transaction log into the distribution database, which acts as a reliable store-and-forward queue. The Distribution Agent copies the initial snapshot files from the snapshot folder and the transactions held in the distribution database tables to Subscribers.
Incremental changes made at the Publisher flow to Subscribers according to the schedule of the Distribution Agent, which can run continuously for minimal latency, or at scheduled intervals. Because changes to the data must be made at the Publisher (when transactional replication is used without immediate updating or queued updating options), update conflicts are avoided. Ultimately, all Subscribers will achieve the same values as the Publisher. If immediate updating or queued updating options are used with transactional replication, updates can be made at the Subscriber, and with queued updating, conflicts might occur.
The following illustration shows the principal components of transactional replication.

Initial Dataset
Before a new transactional replication Subscriber can receive incremental changes from a Publisher, the Subscriber must contain tables with the same schema and data as the tables at the Publisher. The initial dataset is typically a snapshot that is created by the Snapshot Agent and distributed and applied by the Distribution Agent. The initial dataset can also be supplied through a backup or other means, such as SQL Server Integration Services.
When snapshots are distributed and applied to Subscribers, only those Subscribers waiting for initial snapshots are affected. Other Subscribers to that publication (those that have already been initialized) are unaffected.
Concurrent Snapshot Processing
Snapshot replication places shared locks on all tables published as part of replication for the duration of snapshot generation. This can prevent updates from being made on the publishing tables. Concurrent snapshot processing, the default with transactional replication, does not hold the share locks in place during the entire snapshot generation, which allows users to continue working uninterrupted while replication creates initial snapshot files.
Snapshot Agent
The procedures by which the Snapshot Agent implements the initial snapshot in transactional replication are the same procedures used in snapshot replication (except as outlined above with regard to concurrent snapshot processing).
After the snapshot files have been generated, you can view them in the snapshot folder using Microsoft Windows Explorer.
Modifying Data and the Log Reader Agent
The Log Reader Agent runs at the Distributor; it typically runs continuously, but can also run according to a schedule you establish. When executing, the Log Reader Agent first reads the publication transaction log (the same database log used for transaction tracking and recovery during regular SQL Server Database Engine operations) and identifies any INSERT, UPDATE, and DELETE statements, or other modifications made to the data in transactions that have been marked for replication. Next, the agent copies those transactions in batches to the distribution database at the Distributor. The Log Reader Agent uses the internal stored procedure sp_replcmds to get the next set of commands marked for replication from the log. The distribution database then becomes the store-and-forward queue from which changes are sent to Subscribers. Only committed transactions are sent to the distribution database.
After the entire batch of transactions has been written successfully to the distribution database, it is committed. Following the commit of each batch of commands to the Distributor, the Log Reader Agent calls sp_repldone to mark where replication was last completed. Finally, the agent marks the rows in the transaction log that are ready to be purged. Rows still waiting to be replicated are not purged.
Transaction commands are stored in the distribution database until they are propagated to all Subscribers or until the maximum distribution retention period has been reached. Subscribers receive transactions in the same order in which they were applied at the Publisher.
Distribution Agent
The Distribution Agent runs at the Distributor for push subscriptions and at the Subscriber for pull subscriptions. The agent moves transactions from the distribution database to the Subscriber. If a subscription is marked for validation, the Distribution Agent also checks whether data at the Publisher and Subscriber match.
SQL Server :: How Snapshot Replication Works
By default, all three types of replication use a snapshot to initialize Subscribers. The SQL Server Snapshot Agent always generates the snapshot files, but the agent that delivers the files differs depending on the type of replication being used. Snapshot replication and transnational replication use the Distribution Agent to deliver the files, whereas merge replication uses the SQL Server Merge Agent. The Snapshot Agent runs at the Distributor. The Distribution Agent and Merge Agent run at the Distributor for push subscriptions, or at Subscribers for pull subscriptions.
Snapshots can be generated and applied either immediately after the subscription is created or according to a schedule set at the time the publication is created. The Snapshot Agent prepares snapshot files containing the schema and data of published tables and database objects, stores the files in the snapshot folder for the Publisher, and records tracking information in the distribution database on the Distributor. You specify a default snapshot folder when you configure a Distributor, but you can specify an alternate location for a publication instead of or in addition to the default.
The following illustration shows the principal components of snapshot replication.

Snapshot Agent
For merge replication, a snapshot is generated every time the Snapshot Agent runs. For transactional replication, snapshot generation depends on the setting of the publication property immediate_sync. If the property is set to TRUE (the default when using the New Publication Wizard), a snapshot is generated every time the Snapshot Agent runs, and it can be applied to a Subscriber at any time. If the property is set to FALSE (the default when using sp_addpublication), the snapshot is generated only if a new subscription has been added since the last Snapshot Agent run; Subscribers must wait for the Snapshot Agent to complete before they can synchronize.
The Snapshot Agent performs the following steps:
- Establishes a connection from the Distributor to the Publisher, and then takes locks on published tables if necessary:
- For merge publications, the Snapshot Agent does not take any locks.
- For transactional publications, by default the Snapshot Agent take locks only during the initial phase of snapshot generation.
- For snapshot publications, locks are held during the entire snapshot generation process.
- Writes a copy of the table schema for each article to a .sch file. If other database objects are published, such as indexes, constraints, stored procedures, views, user-defined functions, and so on, additional script files are generated.
- Copies the data from the published table at the Publisher and writes the data to the snapshot folder. The snapshot is generated as a set of bulk copy program (BCP) files.
- For snapshot and transactional publications, the Snapshot Agent appends rows to the MSrepl_commands and MSrepl_transactions tables in the distribution database. The entries in the MSrepl_commands table are commands indicating the location of .sch and .bcp files, any other snapshot files, and references to any pre- or post-snapshot scripts. The entries in the MSrepl_transactions table are commands relevant to synchronizing the Subscriber.
- Releases any locks on published tables.
During snapshot generation, you cannot make schema changes on published tables. After the snapshot files are generated, you can view them in the snapshot folder using Windows Explorer.
Distribution Agent and Merge Agent
For snapshot publications, each time the Distribution Agent runs for the publication, it moves a new snapshot to each Subscriber that has not yet been synchronized, has been marked for reinitialization, or includes new articles.
For snapshot and transactional replication, the Distribution Agent performs the following steps:
- Establishes a connection to the Distributor.
- Examines the MSrepl_commands and MSrepl_transactions tables in the distribution database on the Distributor. The agent reads the location of the snapshot files from the first table and Subscriber synchronization commands from both tables.
- Applies the schema and commands to the subscription database.
For an unfiltered merge replication publication, the Merge Agent performs the following steps:
- Establishes a connection to the Publisher.
- Examines the sysmergeschemachange table on the Publisher and determines whether there is a new snapshot that should be applied at the Subscriber.
- If a new snapshot is available, the Merge Agent applies to the subscription database the snapshot files from the location specified in sysmergeschemachange.
SQL Server Replication Step by Step
Introduction
Earlier, most of the applications were using standalone environment where a single centralized server was responding to multiple users, working in different locations.
Centralized Approach and Problems
- Performance problems
- Availability problems
- Maintenance problems
To overcome all the above problems, we can use replication solution.
Replication allows to maintain same database multiple copies at different locations. Log shipping and mirroring allows to maintain complete database redundancy whereas replication allows to maintain some part of the database (a set of required objects) at users location. Changes made at different user locations are synchronized to the main server. It is object level high availability feature. According to Books Online:
Replication is a set of technologies for copying and distributing data and database objects from one database to another and then synchronizing between databases to maintain consistency.
Unlike other methods of high availability, it doesn’t distribute entire database, but only distributes some part of database like tables or views.
Advantages
- Improved performance
- To reduce locking conflicts when multiple users are working
- Improved availability
- Easy maintenance
- To allow sites work independently. So that each location can set up its own rules and procedures for working with its copy of the data.
- To move data closer to the user
SQL Server 2005 Features
- Restartable Snapshots
- Oracle Publishing
- Replicating all DDLs
- Merge Replication allows to introduce custom business logic into the synchronization process
- Merge Replication provides the ability to replicate data over HTTP with web synchronization option
- Updatable Transactional Subscriptions can now handle updates to large data types at Subscribers
SQL Server 2008 Features
- In SQL Server 2005, replication had to be stopped in order to perform some actions like adding nodes, making schema changes, etc. But in 2008, these can be done online.
- Conflict detection capacity in peer-to-peer replication.
- All types of conflicts are detected and reported through agent error log or conflicts table.
- In SQL Server 2005, switch partition is unsupported, but in 2008 it supports.
@allow_partition_switch@replicate_partition_switch
- Performance improvements, under Windows 2008
- Snapshot delivery of more than 500MB/minute
- Time to deliver 100000 varbinary(max) records in less than 2minutes where in 2005 223 minutes.
SQL Server 2012 Features
- Updatable subscriptions with transactional publications are discontinued.
- Four new stored procedures provide replication support for AlwaysOn.
sp_get_redirected_publishersp_redirect_publishersp_validate_replica_hosts_as_publisherssp_validate_redirected_publisher
- Replication supports the following features on Availability groups:
- A publication database can be part of an availability group. The publisher instances must share a common distributor.
- In an AlwaysOn Availability Group, an AlwaysOn secondary cannot be a publisher. Republishing is not supported when replication is combined with AlwaysOn.
- Heterogeneous replication to non-SQL Server subscribers is deprecated. To move data, create solutions using change data capture and SSIS.
- Oracle Publishing is deprecated.
Replication Architecture
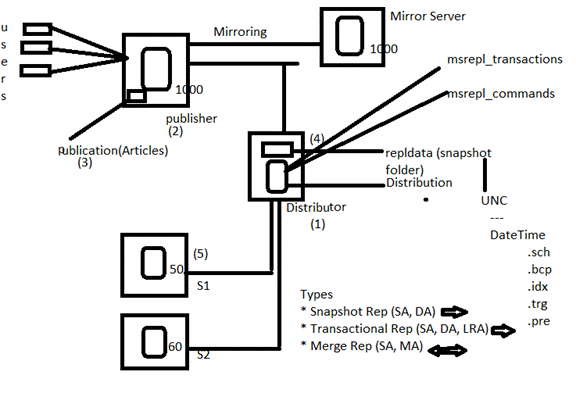
REPLICATION ENTITIES
SQL Server replication is based on the “Publish and Subscribe” metaphor. Let us look at each of the individual components in detail.
- Publisher
- It is a source database where replication starts. It makes data available for replication.
- Publishers define what they publish through a publication.
- Article
- Articles are the actual database objects included in replication like tables, views, indexes, etc.
- An article can be filtered when sent to the subscriber.
- Publication
- A group of articles is called publication.
- An article can’t be distributed individually. Hence publication is required.
- Distributor
- It is intermediary between publisher and subscriber.
- It receives published transactions or snapshots and then stores and forwards these publications to the subscriber.
- It has 6 system databases including distribution.
- Subscriber
- It is the destination database where replication ends.
- It can subscribe to multiple publications from multiple publishers.
- It can send data back to publisher or publish data to other subscribers.
- Subscription
- It is a request by a subscriber to receive a publication.
- We have two types of subscriptions - push and pull.
- Push Subscriptions
- With this subscription, the publisher is responsible for updating all the changes to the subscriber without the subscriber asking those changes.
- Push subscriptions are created at the Publisher server
- Pull Subscriptions -
- With this subscription the subscriber initiates the replication instead of the publisher.
- The subscriptions are created at the Subscriber server.
REPLICATION AGENTS
- We have discussed that replication process works in the background with the help of jobs.
- These jobs are also called as agents. These jobs internally uses respective .exe files present in …………….. \110\COM folder.
- All the agents information is present in Distribution db in the following tables.
dbo.MSxxx_agentsdbo.MSxxx_history
Snapshot Agent
- It is an executable file that prepares snapshot files containing schema and data of published tables and db objects.
- It stores the files in the snapshot folder, and records synchronization jobs in the distribution database.
Distribution Agent
- It is used with snapshot and transactional replication.
- It applies the initial snapshot to the Subscriber and moves transactions held in the Distribution db to Subscribers.
- It runs at either the Distributor for push subscriptions or at the Subscriber for pull subscriptions.
Log Reader Agent
- It is used with transactional replication, which moves transactions marked for replication from the transaction log on the publisher to the distribution db.
- Each db has its own Log Reader Agent that runs on the Distributor and connects to the Publisher.
Merge Agent
- It is used with merge replication.
- It applies the initial snapshot to the Subscriber and moves incremental data changes that occur.
- Each merge subscription has its own Merge Agent that connects to both the Publisher and the Subscriber and updates both.
- It captures changes using triggers.
Queue Reader Agent
- It is used with transactional replication with the queued updating option.
- It runs at the Distributor and moves changes made at the Subscriber back to the Publisher.
- Unlike Distribution Agent and Merge Agent, only one instance of the Queue Reader Agent exists to service all Publishers and publications for a given distribution db.
REPLICATION TYPES
- Snapshot Replication
- Transactional Replication
- Merge Replication
1. Snapshot Replication
- The snapshot process is commonly used to provide the initial set of data and database objects for transactional and merge publications.
- It copies and distributes data and database objects exactly as they appear at the current moment of time.
- Snapshot replication is used to provide the initial data set for transactional and merge replication.
- It can also be used when complete refreshes of data are appropriate (BOL).
- Scenarios
- When the data is not changing frequently.
- If we want to replicate small amount of data.
- To replicate Look-up tables which are not changing frequently.
- It is acceptable to have copies of data that are out of date with respect to the publisher for a period of time
For example, if a sales organization maintains a product price list and the prices are all updated at the same time once or twice each year, replicating the entire snapshot of data after it has changed is recommended.
Snapshot Replication Architecture
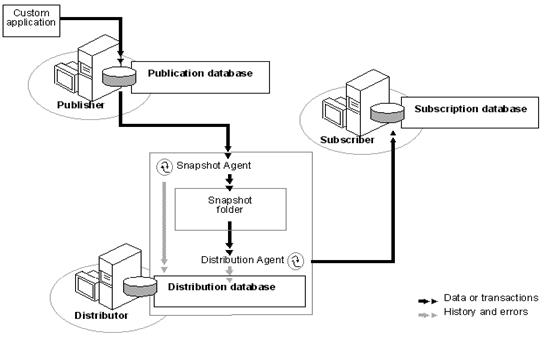
Source: BOL
How it Works?
- Snapshot Agent establish a connection from distributor to publisher and generates fresh snapshot into snapshot folder by placing locks.
- Snapshot agent writes copy of the table schema for each article to .sch file.
- Copies data from published table at the Publisher and writes data to the snapshot folder in the form of.bcp file.
- Appends rows to the
Msrepl_commandsandMsrepl_transactions. - Releases any locks on published tables.
Configuring Replication
- Configuring distributor
- Configuring publisher
- Creating publication of required type
- Creating subscription(s)
Step 1: Configuring distributor and publisher
- Take three instances
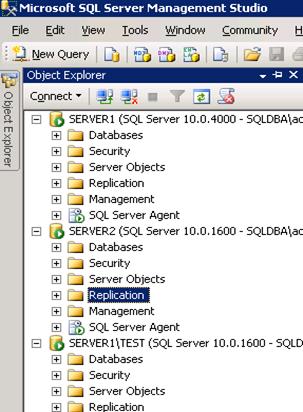
- Go to second instance -> Right click on Replication -> Configure Distribution…
- Next -> Select ‘SERVER2’ will act as its own distributor;
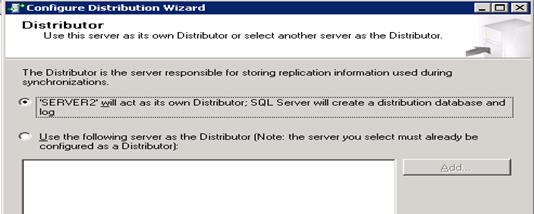
- Next
- Next
- Next
- Uncheck the check box present at Server2 -> Add
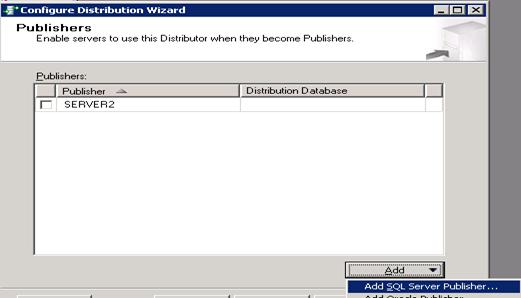
- Select instance Server1
- Next
- Enter strong password. (Automatically one login is created in distributor with the name Distributor_Admin)
- Next
- Next
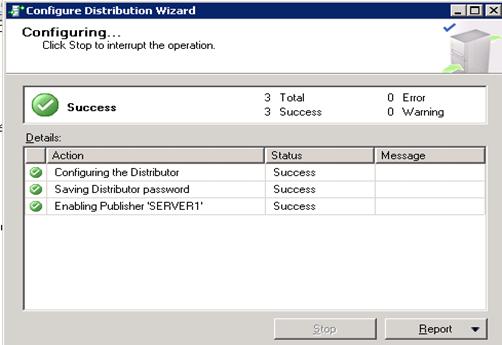
- Finish
Observations
- Go to distributor -> Databases -> Find the new database “
Distribution” - Go to Security -> Logins -> Find a new login “
Distributor_admin” - Go to Server Objects -> Linked servers -> Find new linked server “
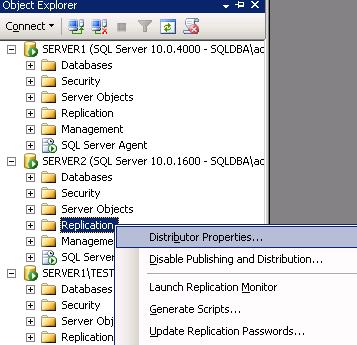
repl_distributor” - Right Click on Replication -> Select distributor Properties
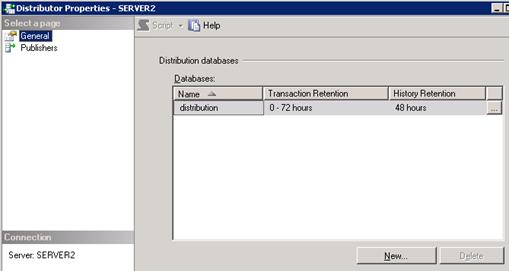
- Transactions stored in distribution database are removed after 72 hrs and agents history is removed after 48 hrs.
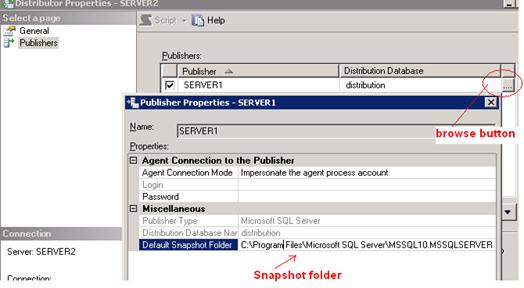
- To view snapshot folder path -> Click on publishers -> click on browse button (…) present to right side of publisher name.
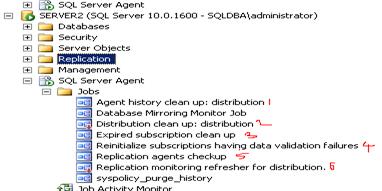
- Go to SQL Server Agent -> Jobs -> Find 6 new jobs are created automatically.
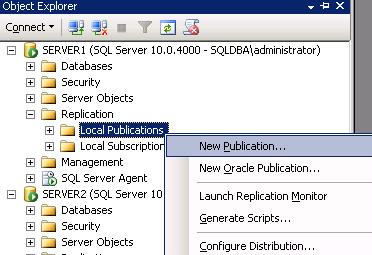
Step 2: Creating Snapshot Publication
- Go to publisher (Server1) -> Replication -> Right Click on Local Publications -> New publication.
- Next
- Select second option -> Click on Add -> Select Distributor instance (
Server2)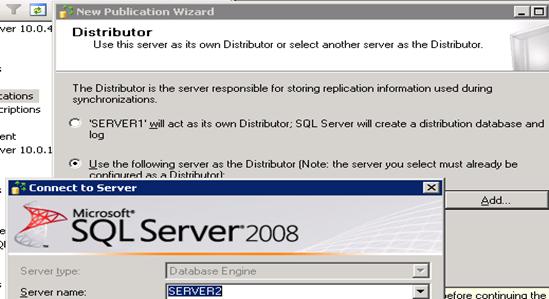
- Connect ? Next
- Enter password of
Distributor_adminlogin which we have mentioned while configuring publisher. - Next
- Select required database. For example
SSISDb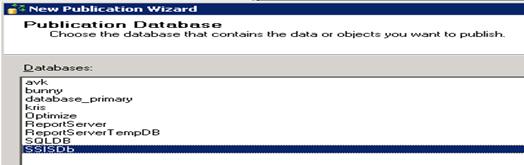
- Next
- Select “Snapshot Publication” -> Next
- Select required tables -> Next
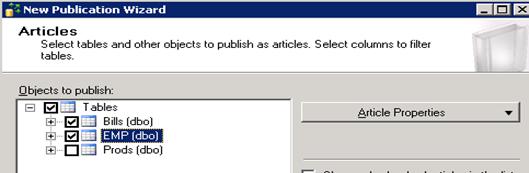
- Next -> Next
- Select the check box to create snapshot as follows
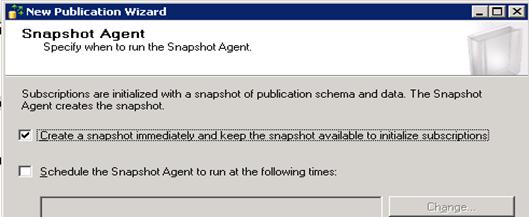
- Next
- Click on security settings
- Select as follows
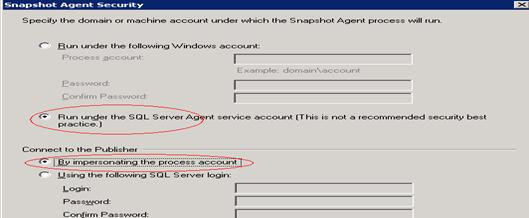
- OK
- Next
- Next -> Next
- Enter publication name as follows
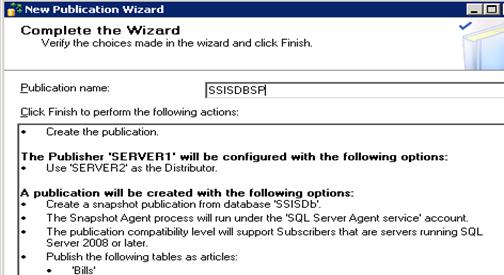
- Finish
Observations
- Go to publisher -> Replication -> Local publications -> Find new publication is created
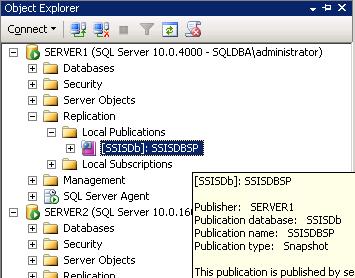
- To check snapshot was created or not -> Right click on the publication (SSISDBSP) -> View Snapshot Agent Status
- Go to repldata folder as follows:
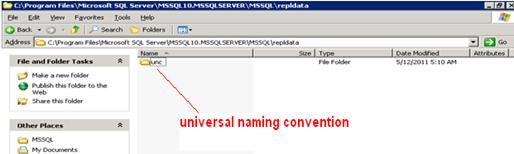
- Go to sub folders find the snapshot files (.bcp, .sch, idx, .trg)
- Go to distributor -> SQL Server Agent -> Jobs -> Find snapshot agent job was created

FAQ: How to display database names which consists of publications?
Ans: Go to publisher -> take new query ->
Hide Copy Code
select name from sys.databases where is_published=1 or is_subscribed=1
Creating Subscription
- Go to publisher -> Replication -> Local Publications -> Right Click on SSISDBSP -> New Subscription
- Next
- Select the publication name: SSISDBSP
- Next
- Select Push subscriptions
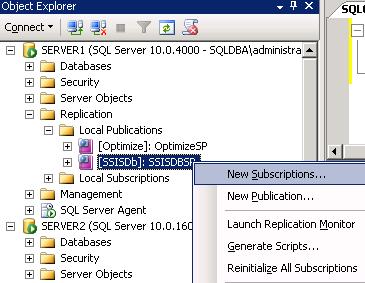
- Next
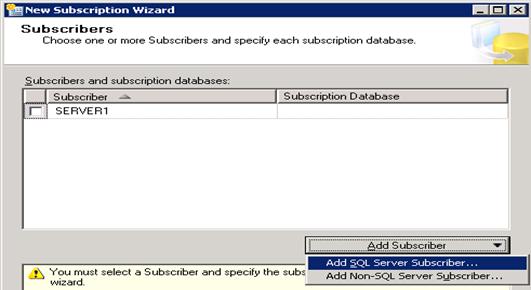
- Add Subscriber -> Select third instance (Server1\test) -> Connect

- Next
- Under Subscription Database if there is no database exists with same name -> Select New database -> Enter Database Name -> OK -> Next
- Click on browse button (…) under distribution agent security page.
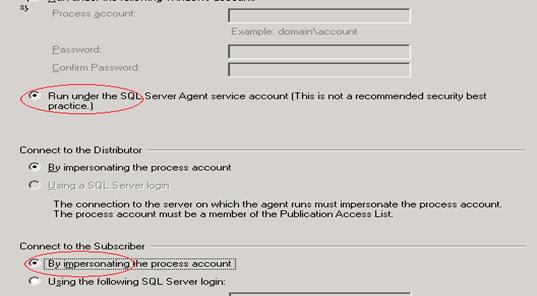
- Select “Run under Agent Service Account” and “By impersonating the process account” options as both distributor and subscriber’s service accounts are same. If the service account of subscriber is different, then create a login in subscriber with sysadmin privileges then mention that login details.
- Next
- Under Agent Schedule -> Select “Run Continuously”
- Under Initialize when select -> Immediately
- Next -> Next -> Finish
Observations
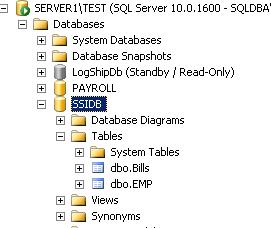
- Go to subscriber -> SSISDB -> Tables -> Find two tables are created
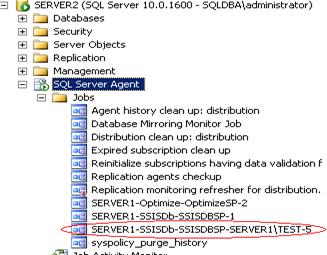
- Go to distributor -> SQL Server Agent -> Find new job is created, related to Distribution Agent
Verifying Replication
- Go to publisher perform some changes in any table present in publication
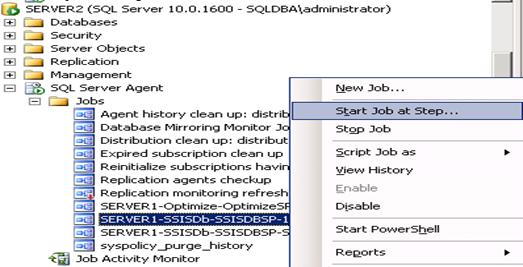
- Go to distributor run Snapshot Agent Job
- Go to subscriber observe the changes in the respective table
FAQ: How many articles may be there in a snapshot publication?
32767
32767
FAQ: Max columns in a table?
1000
1000
Subscribe to:
Posts (Atom)